- Published on
Why We Built Daana: Reclaiming Lost Knowledge
- Authors

- Name
- Siavoush Mohammadi

The Knowledge That Was Lost
I started my career in Stockholm around 2010, learning from experienced data architects and engineers (we used to be called ETL developers) who took modeling seriously. Data modeling wasn't optional - it was foundational. Every data professional learned Kimball's dimensional modeling, Inmon's enterprise warehouses, normal forms, ensemble modeling techniques like Data Vault. We understood that how you structured data mattered as much as what you captured.
These weren't abstract theories but proven patterns for building systems that could grow without collapsing under complexity. Proper modeling meant source system changes didn't cascade chaotically. Business logic lived in well-defined places. New team members understood the system by examining the model.
Then came the "big data" revolution. To some dismay (maaaybe a little understatement) a generation of data professionals was told: "You don't need to model. Just throw it in the data lake." Schema on read, not schema on write. ELT replaced ETL. Store everything raw and figure it out later. The lake became a swamp.
The problem wasn't the technology - distributed storage and processing unlocked genuine new capabilities. The problem was discarding decades of architectural knowledge because the new tools didn't enforce it. We went from "model carefully" to "modeling is old-school, just dump it all in."
Teams stopped teaching data modeling because it seemed irrelevant. Senior architects who carried this knowledge retired or moved on. Junior engineers never learned it because companies didn't practice it. The skills that made data systems comprehensible became concentrated in a shrinking pool of practitioners.
The pendulum swung too far. We gained powerful tools but lost the discipline that made data platforms sustainable. Now, 10-15 years later, we're living with the consequences.
The Consequences We're Living With
You've seen this. Maybe you're living it right now. Data engineers drowning in unmaintainable hand-written SQL. Pipelines that break at 3 AM because some upstream column changed and nobody documented the dependency. Data quality issues that erode trust until stakeholders quietly build their own spreadsheets and stop asking the data team for anything. And no, throwing AI at it won't really help.
The chaos manifests predictably. Point-to-point solutions with no coherent structure. "Medallion architectures" where bronze, silver, and gold layers exist in name only - ask three people what belongs in silver and you'll get four answers. Transformation logic scattered randomly. Business rules duplicated in five places, each implementation uniquely wrong.
Junior engineers write SQL reflecting no understanding of separation of concerns or semantic clarity. You can't practice what you were never exposed to.
Senior engineers hold critical knowledge in their heads with no way to preserve it structurally. They know which transformations are fragile, which sources can't be trusted, where hidden dependencies lurk. But this exists as tribal lore, not captured in any system. When they leave, that knowledge walks out the door with them. I've watched this happen multiple times - an entire platform's architectural rationale vanishing with a single resignation.
Every company rebuilds the same transformation patterns badly. Same mistakes. Same brittle approaches. Same late discovery that mixing source representation with business logic makes everything unmaintainable. It's like watching people individually discover that fire is hot.
The symptom everyone sees is brittle pipelines requiring constant manual intervention. The root cause runs deeper - we stopped teaching the disciplines that made data systems maintainable, and now we're paying the price in toil and fragility.
What We Lost (And Why It Mattered)
Data modeling isn't about resisting innovation. It's about understanding what you're building semantically - separation of concerns, knowing what belongs where and why. Clear interfaces between layers so changes don't ripple unpredictably. Systems comprehensible to humans and AI.
Different modeling approaches serve different purposes, and a practitioner picks between them based on the problem at hand. When you need to capture how the business actually works - handling source systems that change underneath you while preserving historical context - that's where ensemble modeling techniques earn their keep in the Data As Business (DAB) layer. When you're shaping data for how people actually analyze it, dimensional modeling remains the natural choice for the Data As Requirements (DAR) layer. Normalized models fit operational reporting. Event-driven patterns handle real-time needs.
These aren't competing philosophies - they're complementary techniques for different layers. The three-layer architecture (Data As System sees it, Data As Business sees it, Data As Requirements needs it) provides clear separation - if you know staging/core/marts or bronze/silver/gold, this is the same concept with names that encode purpose rather than position. Source changes stay isolated in DAS. Business semantics stabilize in DAB. Consumption patterns in DAR evolve without touching upstream layers. And YES, the names sound a bit boring, BUT they are explicit and informative, that's why we prefer them.
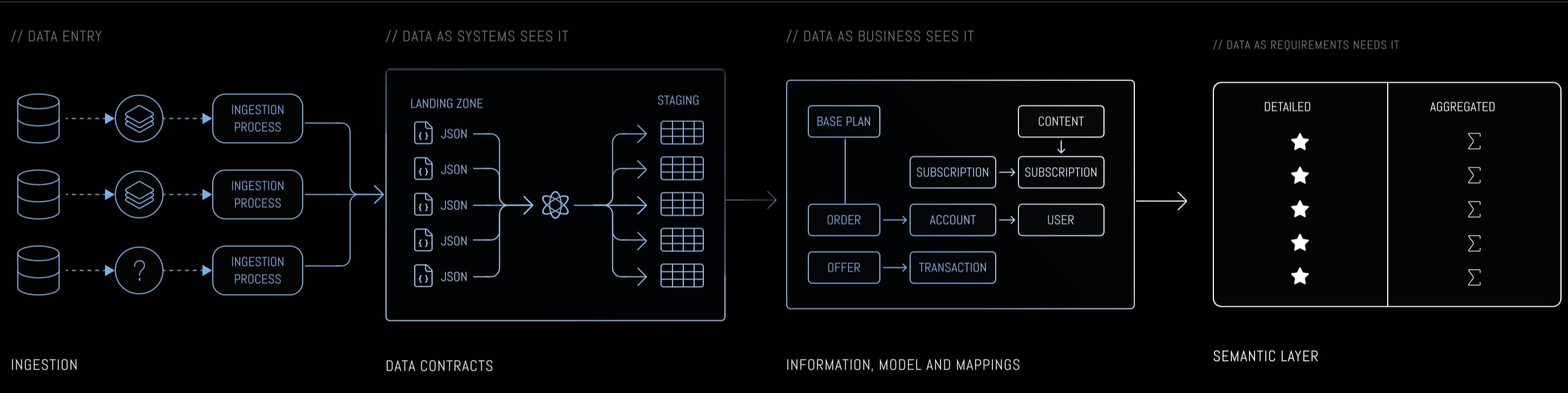
The three-layer architecture enables practical patterns like forgiving ingestion and self-healing pipelines - covered in detail in The Rise of the Model-Driven Data Engineer.
But accessing this knowledge requires massive upfront investment. Want to build proper three-layer architecture? You'll spend months designing, implementing, debugging hand-written transformations. By the time you deliver value, stakeholders have lost patience. The business case for doing it right can't compete with shipping something broken next week.
Speeeeecially in the age of AI, where people generally expect faster deliveries than before. The ye olde "I built this dashboard locally in PowerBI, can you JUST put it into production" has now changed to "I asked Claude to build this prototype..." followed by "... can you JUST put it into production" OR "I pushed it to production but now the dataset I used to work with is gone."
This is why knowledge stays concentrated. Only organizations with sufficient resources can invest in building these systems properly. Everyone else cobbles together point-to-point solutions because they have no practical alternative.
What We Gained (And What's Still Missing)
While we lost modeling knowledge, we gained something genuinely valuable. Tools like dbt brought modern software engineering to data work - version control, CI/CD, testing frameworks, code review, infrastructure as code. If you've worked on data projects before and after this shift, you know the difference. We finally got the engineering rigor that software teams had enjoyed for years.
But here's what we didn't get: knowledge of what to build. We have excellent tools for version-controlling SQL that lacks architectural coherence. Testing frameworks validating brittle point-to-point transformations instead of well-designed semantic models. CI/CD pipelines deploying code that reflects no understanding of separation of concerns.
The tools aren't the problem - they work exactly as designed. The problem is that we've gotten very good at deploying bad architecture faster. That's a sentence worth reading twice.
So what if we could have both? Modern engineering practices AND the modeling knowledge to guide what we're building? What if proven patterns were accessible without requiring everyone to become ensemble modeling experts? What if understanding business semantics didn't mean months of design work before anyone sees value?
That's the declarative shift. Declare what you want - business entities, relationships, semantic meaning - and let the system generate how to build it following sound architectural principles. Documentation becomes implementation. Not documentation gathering dust in Confluence while the actual platform drifts in a different direction - documentation that directly drives your platform.
And here's the part that may surprise you: LLMs become dramatically more effective when you have this structure. Feed them hand-written SQL and they can maybe help debug. Feed them semantic definitions of business entities and they can answer domain-specific questions, suggest transformations, identify inconsistencies. But only if you have semantic clarity to begin with. Without structure, you're back to slipping sticky notes under the door.
The path forward isn't choosing between modeling knowledge and modern practices. It's combining them.
Standing on the Shoulders of Giants
Let's be clear about what's new here and what isn't. The modeling techniques behind Daana aren't new. Kimball's dimensional modeling still holds. Three-layer architecture works. Ensemble modeling techniques handle change while preserving history. Data contracts and self-healing pipelines are battle-tested concepts. We didn't invent any of this.
What's new is making these principles accessible through declarative YAML. Encoding the knowledge so teams don't have to rebuild it from scratch every time. And designing for an age where semantic definitions matter because LLMs need structure to be effective - a consideration that didn't exist when Kimball was writing his books.
Humility matters here. Practitioners like Ralph Kimball, Bill Inmon, Hans Hultgren, Dan Linstedt, and countless others solved hard problems and shared what they learned. Our contribution isn't the patterns - it's creating a path for teams to actually use them without years of specialized training or massive upfront investment. We're restoring lost knowledge, not inventing it. That restoration is only possible because the foundations were built by those who came before us.
Why Daana Exists
We built Daana because we kept watching the same problems repeat everywhere we worked. Teams drowning in brittle pipelines. Architectural knowledge concentrated in one or two senior people who couldn't take a vacation without something breaking. The same transformation patterns rebuilt poorly in every organization, as if nobody had ever solved these problems before. But people had - just decades ago, and the knowledge didn't transfer.
We'd seen firsthand how powerful well-modeled systems could be: platforms that remained stable as businesses grew, pipelines that didn't break constantly, architectures that new team members could understand and extend. The knowledge existed. The tooling to deliver it didn't.
Tools existed for writing SQL and orchestrating pipelines. But nothing encoded architectural knowledge itself - no way to capture what works and make it repeatable. The gap between knowing what good architecture looks like and actually building it - that's what we set out to close.
Daana is declarative data modeling for modern platforms. You declare your business entities in YAML - what they are, how they relate, what they mean semantically. The system generates transformation pipelines following proven architectural patterns. It works on BigQuery, Snowflake, and other cloud platforms.
The goal: let data professionals focus on understanding the business. Capturing business processes in information models. Creating value iteratively. Not becoming experts in ensemble modeling techniques, but still enforcing that you actually model with clear purpose and semantic meaning. Not choosing between speed and quality, but getting both.
We deliver this by working directly with teams - building their platforms alongside them, transferring knowledge as we go. The data community built these patterns over decades. Our job is to make them usable again, not by writing another book about dimensional modeling, but by encoding the patterns into tooling that enforces them while you focus on the business.
That's why Daana exists: to make architectural knowledge accessible through tooling. To combine the craft of data modeling with modern engineering practices. To reclaim what was lost.
What This Means in Practice
You define your business entities in YAML - what they are, how they relate, what their attributes mean:
entities:
- id: "CUSTOMER"
name: "CUSTOMER"
definition: "Customer who places orders"
attributes:
- id: "CUSTOMER_NAME"
definition: "Full name of the customer"
type: "STRING"
effective_timestamp: true
- id: "CUSTOMER_CITY"
definition: "City where customer is located"
type: "STRING"
effective_timestamp: true
- id: "CUSTOMER_STATUS"
definition: "Account status (Active, Inactive, Suspended)"
type: "STRING"
effective_timestamp: true
That's one entity. Now add an ORDER_LINE that connects to both ORDER and PRODUCT through named relationships:
- id: "ORDER_LINE"
name: "ORDER_LINE"
definition: "Individual item within an order"
attributes:
- id: "ORDER_LINE_ID"
definition: "Unique line item identifier"
type: "STRING"
effective_timestamp: true
- id: "QUANTITY"
definition: "Number of units purchased"
type: "NUMBER"
effective_timestamp: true
- id: "LINE_AMOUNT"
definition: "Total value of this line item"
type: "NUMBER"
effective_timestamp: true
relationships:
- name: "IS_FOR_PRODUCT"
definition: "Line item references a product"
source_entity_id: "ORDER_LINE"
target_entity_id: "PRODUCT"
- name: "BELONGS_TO"
definition: "Order line belongs to an order"
source_entity_id: "ORDER_LINE"
target_entity_id: "ORDER"
Now you're modeling how business concepts actually relate to each other - not just defining tables, but capturing that an order line IS_FOR a product and BELONGS_TO an order. These relationships drive join logic in the generated views. You don't write the joins - the model does.
You map these entities to source tables - which columns feed which attributes, how to handle timestamps, how to merge data from multiple sources. Then you run two commands: daana-cli deploy and daana-cli execute.
Daana generates transformation logic and creates three views per entity in your data warehouse:
VIEW_CUSTOMER- Current state. One row per customer, latest attribute values.VIEW_CUSTOMER_HIST- Full history. Every change tracked, time-travel ready.VIEW_CUSTOMER_WITH_REL- Current state with relationships already joined.
No historization code written. No SCD2 logic. No temporal join patterns. The entity definition drives everything.
Here's what that enables. Say a customer moved from Boston to Philadelphia on November 29th. You can query any point in time:
-- Where was this customer living on November 27th?
SELECT customer_name, customer_city, customer_state, eff_tmstp
FROM daana_dw.view_customer_hist
WHERE customer_key = '2'
AND eff_tmstp <= '2024-11-27'
ORDER BY eff_tmstp DESC
LIMIT 1;
customer_name | customer_city | customer_state | eff_tmstp
Emily Johnson | Boston | MA | 2024-11-05
Change the date to November 29th and you get Philadelphia. The history built itself from your entity definition and source mappings. For a full walkthrough covering multi-source merging, composite keys, and more complex modeling patterns, see the Daana tutorial.

Your semantic definitions serve triple duty: what you read to understand the business model, what LLMs read when answering questions about your data, and what drives transformation generation. These aren't three separate artifacts that can drift - they're the same source. Update the model, transformations regenerate automatically.
There are trade-offs. Learning declarative modeling requires shifting from imperative SQL thinking. You gain consistency but sacrifice some flexibility in custom transformations. The generated output may not match exactly what you'd hand-build. If you're wondering how this relates to dbt - whether Daana replaces it, sits on top of it, or complements it - that's covered in depth in The Rise of the Model-Driven Data Engineer, along with the full architectural discussion of when declarative makes sense and when to stay imperative.
The shift changes what the work looks like. Hundreds of hand-written SQL models maintaining transformation logic become generated artifacts of a semantic model that you design and evolve. The repetitive, pattern-following work that consumed most of the engineering effort gets automated. What remains is the work that actually requires human judgment: understanding the business, modeling semantics correctly, and making architectural decisions.
The Invitation
This isn't finished. It's a beginning.
This started because we kept watching teams repeat the same expensive mistakes. The data architecture community built incredible patterns over decades - but most teams never get access to them because the knowledge lives in the heads of a few senior practitioners who are stretched too thin to teach.
This is alpha because we're still learning. The core patterns work - we've used them across organizations with consistent results. But translating those into a tool that works for diverse teams requires feedback from people building real systems under real constraints.
This is an invitation because we can't reclaim lost knowledge alone. It takes a community of data engineers, analytics engineers, and architects who believe data platforms should be better than what we've settled for.
If you recognize this problem - if you've watched teams struggle with brittle pipelines and lost architectural knowledge - we want your perspective. What patterns matter most in your context? What barriers prevent adoption? What did we get wrong?
Sign up at daana.dev to try it on your own data and tell us what you think. Free to get started - we want feedback from people building real systems.
The data architecture community built incredible knowledge over decades. Let's make sure the next generation can access it.