- Published on
Contract-Driven Data Transformation
- Authors

- Name
- Siavoush Mohammadi

We've all written repetitive pipelines, especially close to where data actually lands from whatever ingestion process has been set up. Somewhere around your fifteenth staging table, a pattern emerges. You open a SQL file written six months ago by a colleague who has since moved teams, and you see a COALESCE wrapping a SAFE_CAST wrapping a JSON_VALUE. Is this handling a known source system quirk, or is it a workaround for bad data that got hot-fixed months ago? You have no way to tell, because the shadow of the knowledge lives only inside the SQL - the actual knowledge left with the developer's head once upon a time. The original author knew why that COALESCE was there. Now it is tribal knowledge embedded in code, and the only safe move is to leave it alone and copy the pattern to your next staging file. I saw this meme once that hit home, because I've actually seen similar comments in production code:
// Dear programmer:
// When I wrote this code, only god and
// I knew how it worked.
// Now, only god knows it!
//
// Therefore, if you are trying to optimize
// this routine and it fails (most surely),
// please increase this counter as a warning
// for the next person:
//
// total_hours_wasted_here = 254
That is the real cost of hand-written staging SQL. Not the initial writing - that part is fast. The cost is in the thirtieth file, when five different engineers have each made slightly different decisions about timestamp parsing, null handling, and type casting, and the staging layer has quietly become a collection of undocumented micro-decisions that nobody can reason about as a whole.
Let's zoom into the first layer of the three-layer architecture - Data As the System sees it (DAS), where source system data gets unpacked from raw JSON into typed, structured staging tables. The pattern: replace hand-written staging SQL with declarative YAML contracts. A generator reads contracts and produces SQL. The contract becomes the documentation, the schema definition, and the transformation logic - all in one artifact. Change the contract, regenerate the SQL. No drift possible.
The tooling for each layer is interchangeable. Ingestion might be Airbyte, dlt, Fivetran, or custom scripts. The generator outputs vanilla SQL that could run as Dataform SQLX, dbt models, or plain SQL files executed by any scheduler. The architecture is the point, not the vendor stack. We happen to use Dataform on BigQuery in our reference implementation, but every concept here translates directly to dbt on Snowflake or Postgres.
We'll use Acme Streaming as our running example - a subscription-based streaming service with five source systems: Kafka event streams, MySQL CDC via Debezium, REST API snapshots, webhook events, and batch file drops. Each system delivers data in its own format and cadence. The staging layer needs to handle all of them consistently, and that consistency is exactly what hand-written SQL struggles to maintain.
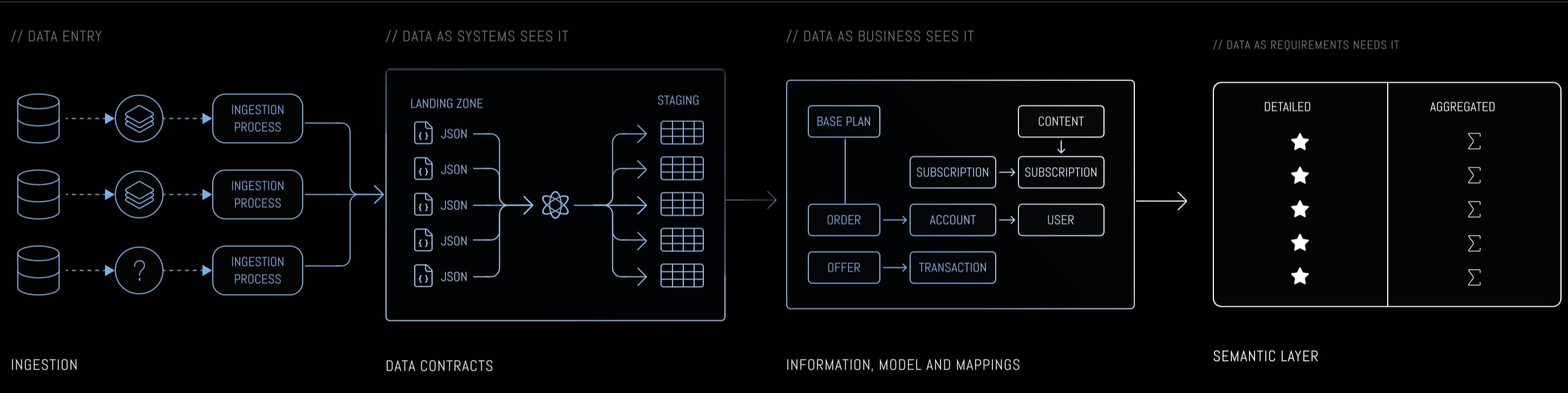
We're living entirely in the DAS box above - the section labeled "Data Contracts" where raw JSON from the landing zone gets unpacked into typed staging tables. Everything to the right (business modeling, semantic layer) consumes what DAS produces, and the quality of that consumption depends on how consistently the staging layer handles its sources.
Anatomy of a Data Contract
The structure of these data contracts - YAML with source, target, ownership, and schema sections - was inspired by Robert Sahlin's description of MatHem's data contracts in his DataHem Odyssey series.
A contract for streaming.evt_subscription_state - Acme's subscription state transition events from Kafka - looks like this:
endpoints:
source:
provider: kafka
entity: evt_subscription_state
target:
models:
- type: historized
cadence: hourly
- type: latest
cadence: daily
ownership:
team: Platform
repository: https://github.com/acme-streaming/data-contracts
schema:
primary_keys:
- account_id
- cycle_id
columns:
- source_path: account_id
target_name: account_id
type: STRING
mode: REQUIRED
description: "Account identifier, FK to evt_account_state"
- source_path: cycle_id
target_name: cycle_id
type: INTEGER
mode: REQUIRED
description: "Subscription cycle number. 0=visitor, 1+=real cycles"
- source_path: current_state
target_name: current_state
type: STRING
mode: REQUIRED
description: "State after transition. Values: VISITOR, FREE_TRIAL,
MEMBER_PAYING, MEMBER_CAMPAIGN, NONMEMBER"
- source_path: plan_id
target_name: plan_id
type: INTEGER
mode: NULLABLE
description: "FK to cdc.plans. NULL during visitor/trial states"
- source_path: campaign_id
target_name: campaign_id
type: INTEGER
mode: NULLABLE
description: "FK to cdc.campaigns. Present only for campaign-driven transitions"
- source_path: is_b2b
target_name: is_b2b
type: BOOLEAN
mode: REQUIRED
description: "Whether this is a B2B (business) subscription"
- source_path: event_ts
target_name: event_ts
type: TIMESTAMP
mode: REQUIRED
description: "When the state transition occurred, ISO 8601"
Reading top to bottom: endpoints declare where data comes from (Kafka) and what models to generate. We don't bother with version fields inside the contract - contracts live in Git, and commit history is a better versioning mechanism than anything we could invent. When someone changes a column type or removes a field, the diff shows exactly what changed and when.
Here we want both: a historized table that keeps every state transition as an append-only log, and a latest view showing the most recent state per entity. The generator builds both from the same contract - the historized model is a straightforward SELECT, while the latest model adds a window function partitioned by the primary keys and ordered by the event timestamp.
Where it gets interesting is the schema block. Primary keys define deduplication logic, and each column maps a source path to a typed target with an explicit mode. campaign_id is NULLABLE INTEGER - so the generated SQL uses SAFE_CAST and won't fail when the value is missing. event_ts is TIMESTAMP - so the generator uses timestamp parsing, not string extraction. Change the contract, the SQL changes with it. No separate documentation to update, because the contract is the documentation. See, we finally got our dream, writing documentation and test cases for everything! Jokes aside, writing docs used to be "boring" because we knew that it wouldn't reflect reality anyway. This is different.
Notice the composite primary key: account_id + cycle_id. A single account can go through multiple subscription cycles - trial, cancel, re-subscribe. Each cycle gets its own cycle_id, and the combination uniquely identifies a subscription lifecycle. This matters when generating the latest view, because the deduplication window must partition by both fields. The generator takes the same SELECT from the historized model and adds a QUALIFY clause:
-- Latest model: same JSON extraction as historized, plus deduplication
SELECT
JSON_VALUE(_raw_data, '$.account_id') AS account_id,
-- ... same type-cast expressions as historized model ...
SAFE.PARSE_TIMESTAMP('%Y-%m-%dT%H:%M:%E*SZ',
JSON_VALUE(_raw_data, '$.event_ts')) AS event_ts
FROM `acme_streaming.streaming_raw.evt_subscription_state`
QUALIFY ROW_NUMBER() OVER (
PARTITION BY account_id, cycle_id
ORDER BY event_ts DESC
) = 1
One contract, two models. The historized table keeps every state transition. The latest view keeps only the most recent row per subscription cycle. Both are generated from the same schema - the only difference is whether the generator appends the QUALIFY window.
From Contract to SQL - The Generator Pattern
That contract produces SQL. The mapping between YAML types and SQL expressions is mechanical, which is precisely the point - mechanical work should be done by machines, not people who have better things to think about. STRING fields become JSON_VALUE(...) with no cast needed. INTEGER becomes SAFE_CAST(JSON_VALUE(...) AS INT64). TIMESTAMP gets an ISO string parser. BOOLEAN needs special handling - we'll get to that. The generated output for evt_subscription_state:
-- Generated from contract: evt_subscription_state
-- This example uses BigQuery SQL syntax. The same contract generates
-- equivalent Snowflake, Postgres, or Redshift SQL - the contract is
-- the constant, the SQL dialect is the variable.
SELECT
JSON_VALUE(_raw_data, '$.account_id')
AS account_id,
SAFE_CAST(JSON_VALUE(_raw_data, '$.cycle_id') AS INT64)
AS cycle_id,
JSON_VALUE(_raw_data, '$.current_state')
AS current_state,
SAFE_CAST(JSON_VALUE(_raw_data, '$.plan_id') AS INT64)
AS plan_id,
SAFE_CAST(JSON_VALUE(_raw_data, '$.campaign_id') AS INT64)
AS campaign_id,
SAFE_CAST(JSON_VALUE(_raw_data, '$.is_b2b') AS BOOL)
AS is_b2b,
SAFE.PARSE_TIMESTAMP(
'%Y-%m-%dT%H:%M:%E*SZ',
JSON_VALUE(_raw_data, '$.event_ts')
) AS event_ts,
CONCAT(
JSON_VALUE(_raw_data, '$.account_id'),
'-',
CAST(SAFE_CAST(JSON_VALUE(_raw_data, '$.cycle_id') AS INT64) AS STRING)
) AS _pk
FROM `acme_streaming.streaming_raw.evt_subscription_state`
So what does the generator actually look like? It's not complicated, but I get if it might look a bit big, tried to include everything so it would be easy for you to point an AI to the article and re-create the same pattern for your use-case and tech stack. Here is the full decision flow - every path the generator can take from contract to SQL:
At its core, it is a dictionary lookup and a loop:
TYPE_CASTS = {
"STRING": "JSON_VALUE(_raw_data, '{path}')",
"INTEGER": "SAFE_CAST(JSON_VALUE(_raw_data, '{path}') AS INT64)",
"FLOAT": "SAFE_CAST(JSON_VALUE(_raw_data, '{path}') AS FLOAT64)",
"BOOLEAN": "SAFE_CAST(JSON_VALUE(_raw_data, '{path}') AS BOOL)",
"TIMESTAMP": "SAFE.PARSE_TIMESTAMP('%Y-%m-%dT%H:%M:%E*SZ', JSON_VALUE(_raw_data, '{path}'))",
"TIMESTAMP_MILLIS": "TIMESTAMP_MILLIS(SAFE_CAST(JSON_VALUE(_raw_data, '{path}') AS INT64))",
}
contract = load_yaml(contract_path)
select_clauses = []
for column in contract["schema"]["columns"]:
path = f"$.{column['source_path']}"
sql_expr = TYPE_CASTS[column["type"]].format(path=path)
select_clauses.append(f" {sql_expr} AS {column['target_name']}")
print(f"SELECT\n{',\n'.join(select_clauses)}\nFROM {source_table}")
One type, one SQL template. One column, one SELECT clause. The complexity lives in the dictionary, not in the loop - and that is where edge cases accumulate over time. When you discover that MySQL booleans need a COALESCE fallback, you add a "BOOLEAN_CDC" entry to the dictionary. When a new timestamp format appears, you add a "TIMESTAMP_SECONDS" entry. The loop never changes.
One thing worth calling out: the composite primary key gets a separator in the CONCAT - this is not cosmetic. Without the hyphen, CONCAT('A001', CAST(12 AS STRING)) produces 'A00112', and CONCAT('A0011', CAST(2 AS STRING)) also produces 'A00112'. Two different subscriptions, one primary key. The separator makes 'A001-12' and 'A0011-2' distinct. Small detail, real bug.
This looks straightforward for clean types. It gets interesting when source systems disagree about what a value looks like.
Edge Cases the Contract Handles
Now open the contract for cdc.plans - Acme's plan definitions from MySQL via Debezium - and look at the is_active field. Each plan has an is_active flag, declared as BOOLEAN. Simple enough, right? Except MySQL sends boolean values as "true"/"false" in some connector versions and "1"/"0" in others. Whether you get strings or integers depends on the Debezium connector version, the MySQL column definition, and honestly sometimes what day of the week it is. A plain SAFE_CAST(... AS BOOL) handles the string case fine. For the integer case, BigQuery quietly returns NULL - a silent failure that turns every plan's active status into "unknown" without raising an error anywhere. The generator knows about this ambiguity because we learned it the hard way. When it sees a BOOLEAN type on a CDC source, it produces a COALESCE pattern:
COALESCE(
SAFE_CAST(JSON_VALUE(_raw_data, '$.is_active') AS BOOL),
SAFE_CAST(JSON_VALUE(_raw_data, '$.is_active') AS INT64) = 1
) AS is_active
The first branch catches string booleans, the second catches integer booleans. You write this logic once in the generator, and every contract with a BOOLEAN field from a MySQL CDC source benefits automatically. The alternative? Remembering to add the COALESCE by hand in every staging file that touches a boolean from MySQL. And then remembering again six months later when a new table arrives. Good luck with that.
Now look at timestamps across Acme's sources. streaming.evt_subscription_state sends event_ts as an ISO timestamp string. cdc.plans sends _ts_ms as a BIGINT - milliseconds since epoch. api_extract.partners sends _extracted_at as an ISO TIMESTAMP. batch.daily_usage sends batch_date as a DATE. Four sources, four timestamp representations. If you're hand-writing SQL, you need to remember which conversion function goes with which source, every time, for every table. The contract makes this explicit by distinguishing TIMESTAMP, TIMESTAMP_MILLIS, TIMESTAMP_SECONDS, and DATE as separate types. The generator picks the right function:
-- TIMESTAMP (ISO string): streaming.evt_subscription_state.event_ts
SAFE.PARSE_TIMESTAMP('%Y-%m-%dT%H:%M:%E*SZ', JSON_VALUE(_raw_data, '$.event_ts'))
-- TIMESTAMP_MILLIS (BIGINT): cdc.plans._ts_ms
TIMESTAMP_MILLIS(SAFE_CAST(JSON_VALUE(_raw_data, '$._ts_ms') AS INT64))
No guessing, no remembering. The contract declares the format; the generator handles the conversion.
These aren't hypothetical edge cases. The boolean ambiguity cost us hours of debugging before we realized half our flags were silently NULL. The timestamp inconsistency caused a report to show events from 1970 - if you've ever seen that, you know immediately: someone parsed a zero-value BIGINT as an ISO string. Contracts encode those lessons so you learn them once, and the generator applies them to every table that matches the pattern.
Testing Generated Code
Generated code still needs validation - but here's where having contracts makes testing surprisingly pleasant. With hand-written SQL, testing is a guessing exercise: which fields should we check? What partition strategy? When something is NULL, is that a bug or just how the source works? Nobody knows without digging into the source system.
With contracts, the schema IS the test specification. Every field has a declared type and mode, so a NULL where the contract says REQUIRED is mechanically diagnosable. No guessing, no "let me check with the source team."
We run this in tiers. Syntax dry-runs generate the SQL and validate it parses without executing against the warehouse. Zero compute cost. Run this in CI on every contract change, and you catch typos before they reach production.
The interesting tier is null detection. Run the generated SQL against real data, check for unexpected NULLs in REQUIRED fields, and let the contract tell you what the result means:
field: campaign_id mode: NULLABLE nulls: 100% → EXPECTED (mode allows NULL)
field: current_state mode: REQUIRED nulls: 100% → INVESTIGATE
raw check: $.current_state exists in source JSON?
YES → EXTRACTION BUG (source path or type cast is wrong)
NO → SOURCE CHANGED (field no longer exists, update contract)
That distinction between "bug" and "expected" is mechanical when you have the contract as an anchor. Without it, every NULL is ambiguous and you're back to guessing. The whole process costs roughly $0.15 per run on a cloud warehouse - cheap enough to run on every PR.
Here's what really matters across all these tiers: you validate the pattern once, then trust it for every contract that follows it. Fix a boolean casting bug in the generator, and every BOOLEAN field across all contracts is fixed. Improve the timestamp parsing, and every pipeline benefits. Testing effort scales with the number of distinct patterns in your generator, not with the number of source tables. And because the contract declares every field's type, mode, and source path, test coverage is exhaustive by default - no separate test code to write or maintain.
Why Not Just Let AI Write the SQL?
Fair question in 2026: if AI can generate SQL from a source description, why bother with contracts at all? Just point an agent at the source table, describe what you need, and let it write the staging query. It'll probably get it right the first time.
The problem isn't the first time. The problem is the thirtieth time, when thirty different prompts have produced thirty slightly different SQL files, each reflecting whatever the agent decided was the best approach that day. One uses COALESCE for boolean handling, another uses a CASE statement. One parses timestamps with PARSE_TIMESTAMP, another uses TIMESTAMP_MILLIS for the same ISO format because the prompt was worded differently. The agent makes locally reasonable decisions every time, and the staging layer ends up in exactly the same state as if thirty different engineers had each hand-written their own SQL. The mess isn't caused by humans or AI - it's caused by the absence of a shared specification.
Contracts solve this regardless of who or what generates the SQL. When an AI agent reads a contract that says is_active is BOOLEAN from a MySQL CDC source, it doesn't need to decide how to handle boolean ambiguity - the generator already encodes that decision. When a new team member looks at a staging table, they read the contract, not the SQL. The contract is the shared specification that makes both human and AI contributions deterministic.
This is also why contracts are a layer of abstraction worth paying for - but only at scale. For three source tables, just hand-write the SQL and move on with your life. The overhead of maintaining contracts and a generator isn't justified when you can see the entire staging layer on a single screen. For thirty tables, the math flips. One contract change propagates consistently across all generated SQL. One generator fix addresses an entire bug class at once. This article describes the pattern - there are plenty of infrastructure and performance optimizations to consider when running it at scale (storage formats, materialization strategies, incremental loading), but those are implementation details that vary by stack. The architecture stays the same: put the knowledge in the contract, let the machine handle the SQL.